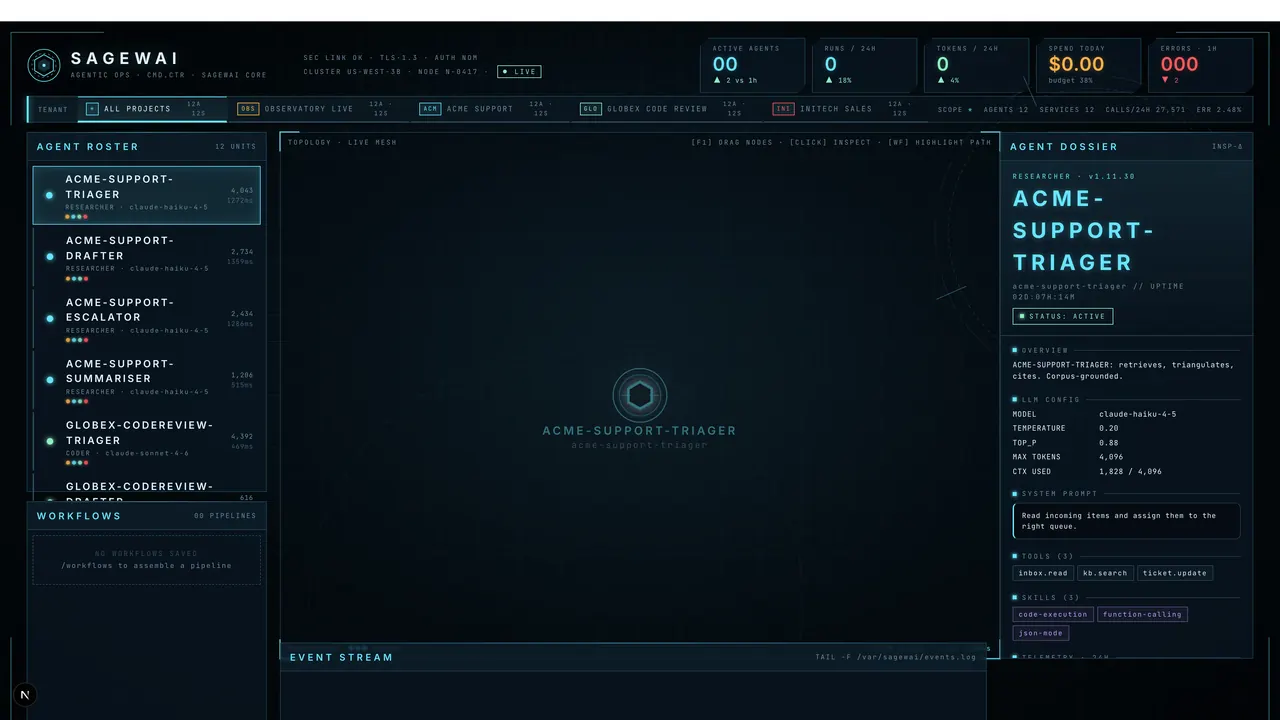


SDK — the harness that works with any LLM.
Tool calling, MCP, memory, workflows, directives. Swap Anthropic for OpenAI for Ollama without changing app code. The directive library translates one prompt into every model's format. Build once, run anywhere — including the local 7B you'll fine-tune in Q3.
from sagewai import Agent
agent = Agent(model="claude-sonnet-4-6")
reply = agent.run("triage this email", tools=[escalate, draft])
# swap to "ollama/llama3.2" — no other change needed